人機交互的數據庫搭建過程
截至數據庫發布當天,徐明團隊用7個月時間得到了4132個單元過程數據。“超過某些國際知名數據庫10年的數據搜集量。”徐明說。
效率之所以高,是因為團隊利用國內AI基礎模型,開發了專門適用天工數據庫建設的大語言模型應用工具,在數據庫搭建過程中實現人機交互。
AI提升數據檢索效率。徐明團隊成員、清華大學環境學院助理研究員齊劍川以對二氧化碳的檢索舉例說:“如果沒有大語言模型應用工具,團隊在檢索二氧化碳時,可能需要輸入‘二氧化碳’‘CO2’‘carbon dioxide’等其不同語言和形式的名稱,才能檢索完備。而在大語言模型工具的幫助下,我們只需輸入上述名稱中的任何一個,就能把想找的所有內容檢索出來,大幅提升了效率。”
AI提升數據檢驗效率。徐明介紹,每名團隊專家按照預先制定的標準搜集數據后,會有另外兩名專家對數據質量進行交叉檢驗。同時,大語言模型應用工具作為第三名“專家”可查找出其檢驗能力范圍內的問題。
齊劍川表示,大語言模型應用工具可以將團隊成員搜集的單元過程數據自動轉換成搭建數據庫所需的ILCD數據格式,進一步提升數據庫建設效率。
“我們還在不斷升級大語言模型應用,擴展人機交互邊界,目標是把重復性、機械性的勞動都交給機器來做,讓團隊專家專注于貢獻增量知識。”齊劍川說。
本`文-內.容.來.自:中`國^碳`排*放*交^易^網 ta np ai fan g.com
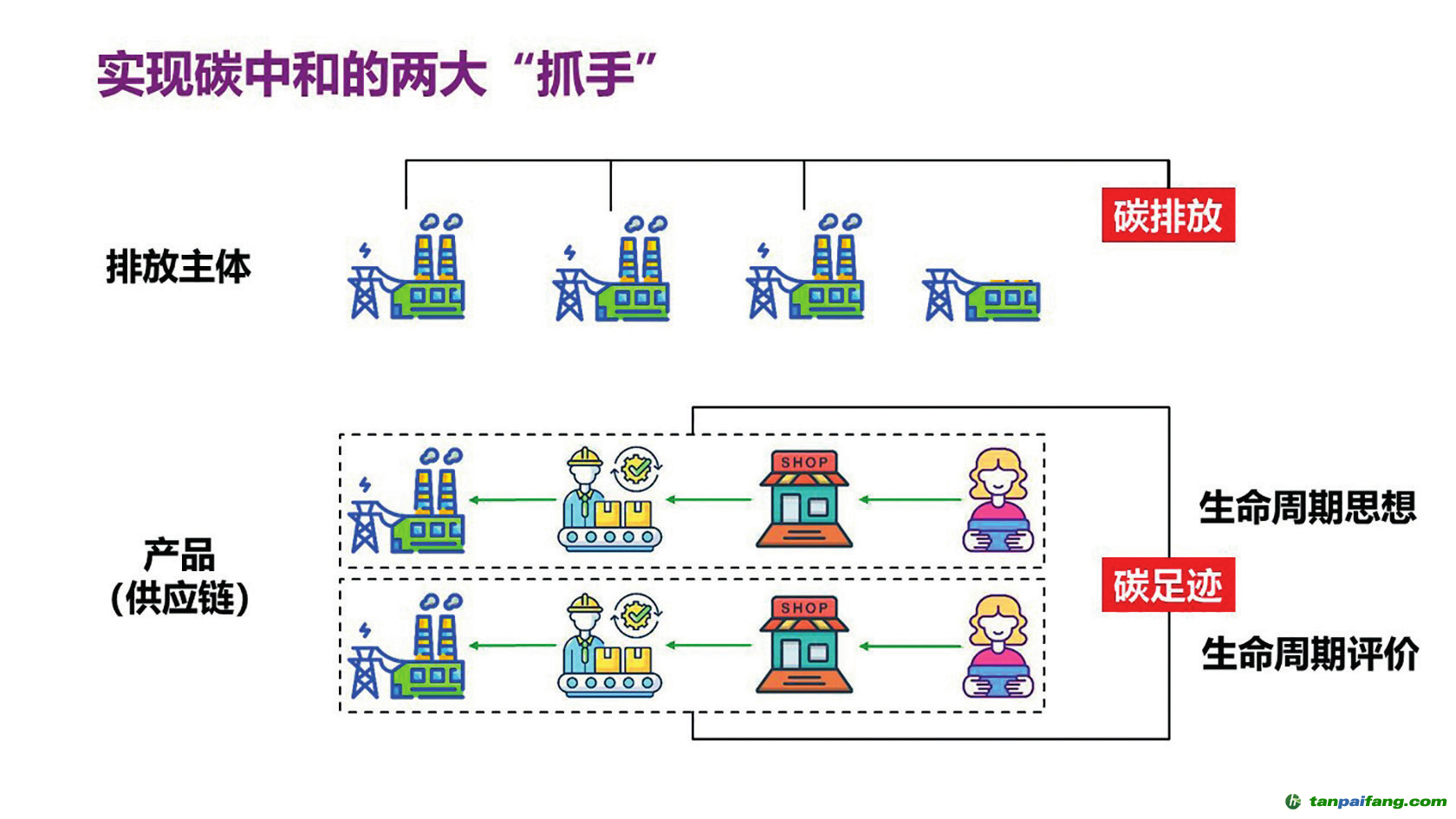
產品碳足跡不以排放主體而以產品為抓手來衡量減排水平
【版權聲明】本網為公益類網站,本網站刊載的所有內容,均已署名來源和作者,僅供訪問者個人學習、研究或欣賞之用,如有侵權請權利人予以告知,本站將立即做刪除處理(QQ:51999076)。