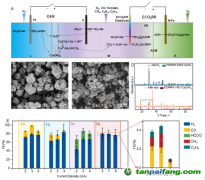
北京時間 2 月 13 日消息,隨著 ChatGPT 的爆紅,微軟、谷歌、百度相繼宣布對他們的搜索引擎進行重大改革,試圖將大型人工智能模型整合到搜索中,以便給用戶提供更豐富、更準確的體驗。但是興奮之余,新工具背后可能隱藏著一個“骯臟的秘密”。
外媒指出,構建高性能人工智能搜索引擎的競賽很可能需要計算能力的大幅提升,它所產生的后果將是科技公司所需能源和
碳排放量的大幅增加。
英國薩里大學網絡安全教授艾倫?伍德沃德 (Alan Woodward) 表示:“已經有大量資源被用于索引和搜索互聯網內容,但人工智能的整合需要一種不同的火力。它需要處理能力、存儲和高效搜索。每當我們看到在線處理的步驟變化時,我們就會看到大型處理中心所需的電力和冷卻資源的顯著增加。我認為人工智能的整合可能是會走這一步。”
碳排放大增 本文@內/容/來/自:中-國-碳^排-放-交易&*網-tan pai fang . com
訓練大型語言模型 (LLMs) 意味著在大量數據中解析和計算鏈接,這就是為什么它們往往是由擁有大量資源的公司開發的原因,比如為微軟必應搜索提供動力的 ChatGPT,為谷歌聊天機器人“巴德”(Bard) 提供支持的那些語言模型。
“訓練這些模型需要大量的計算能力,”西班牙科魯尼亞大學 (University of Coruña) 計算機科學家卡洛斯?戈麥茲?羅德里古茲 (Carlos Gómez-Rodríguez) 表示,“現在,只有大型科技公司才能訓練他們。”
盡管 OpenAI 和谷歌都沒有透露其產品的計算成本是多少,但研究人員發布的第三方分析預計,ChatGPT 部分依賴的 GPT-3 模型的訓練會消耗 1287 兆瓦時電力,產生 550 多噸的二氧化碳當量,相當于一個人在紐約和舊金山之間往返 550 次。
“這個數字看起來沒有那么糟糕,但你必須考慮到這樣一個事實:你不僅要訓練它,還要執行它,為數百萬用戶服務。”羅德里古茲表示。
而且,把 ChatGPT 作為一個獨立產品使用與把它整合到必應中還有很大不同。投行瑞銀預計,ChatGPT 日均獨立訪問用戶為 1300 萬。相比之下,必應每天要處理 5 億次搜索。
加拿大數據中心公司 QScale 聯合創始人馬丁?布查德 (Martin Bouchard) 認為,根據他對微軟和谷歌搜索計劃的了解,在搜索過程中添加生成式人工智能,需要“每次搜索至少增加 4 到 5 倍的計算量”。
為了滿足搜索引擎用戶的需求,企業必須做出改變。“如果他們要經常重新訓練模型,并添加更多參數之類的東西,這是一個完全不同的規模,”布查德表示,“這將需要在硬件上進行大量投資。我們現有的數據中心和基礎設施將無法應對生成式人工智能的消耗。它們對性能的需求太高了。”
如何減少碳排放?
本*文`內/容/來/自:中-國-碳^排-放“交|易^網-tan pai fang . c o m
根據國際能源署發布的數據,數據中心的溫室氣體排放量已經占到全球溫室氣體排放量的 1% 左右。隨著云計算需求的增長,這一數字預計還會上升,但運營搜索引擎的公司已承諾減少它們對全球變暖的凈貢獻。
微軟已經承諾到 2050 年實現碳負排放,該公司計劃今年購買 150 萬噸
碳信用額。
碳信用又稱碳權,是指排放 1 噸二氧化碳當量的溫室氣體的權利。谷歌承諾到 2030 年在其整個業務和價值鏈實現凈零排放。
對于這些巨頭來說,減少將人工智能整合到搜索中的環境足跡和能源成本的一個方式就是將數據中心轉移到更清潔的能源上,并重新設計神經網絡讓讓變得更高效,減少所謂的“推斷時間”,也就是算法處理新數據所需的計算能力。
“我們必須研究如何減少這種大型模型所需要的推斷時間,”謝菲爾德大學自然語言處理講師納菲斯?薩達特?莫薩維 (Nafise Sadat Moosavi) 表示,她致力于自然語言處理的可持續性研究,“現在是關注效率方面的好時機。”
谷歌發言人簡?帕克 (Jane Park) 表示,谷歌最初發布的“巴德”版本是一個由輕量級大型語言模型支持的版本。“我們還發表了一項研究,詳細介紹了最先進語言模型的能源成本,包括早期和更大版本的 LaMDA,”帕克稱,“我們的研究結果表明,將高效的模型、處理器和數據中心與
清潔能源相結合,可以將機器學習系統的
碳足跡減少 1000 倍。”
【版權聲明】本網為公益類網站,本網站刊載的所有內容,均已署名來源和作者,僅供訪問者個人學習、研究或欣賞之用,如有侵權請權利人予以告知,本站將立即做刪除處理(QQ:51999076)。
关注碳学会微信公众号
免费学习碳交易
业内大咖答疑解惑
安装易碳家APP
碳K线、工具、资讯
专业人士的必备软件